


Introduction
Oftentimes now we hear about parallel programming and parallel execution in order to provide a sustainable architecture where multi-tasking thrives, however, most people consider the aspects of Parallelism and concurrent programs similar which seems correct in the verbal matter but they vary in the technical applications of programming.
Through this blog, we will take a quick dive into the definition of concurrency and how Golang (A compiled programming language designed at Google) provides means of supporting concurrency in a lightweight manner inside an application.
Before we begin
Before we dive into technical details, we might need to highlight a few thoughts since people can be easily misled by the terminology of both if they didn’t have a fair share of developing/running multiple processes simultaneously so they might get easily confused by the upcoming terms. so first things first, let’s start with defining parallel execution Vs concurrent processes:
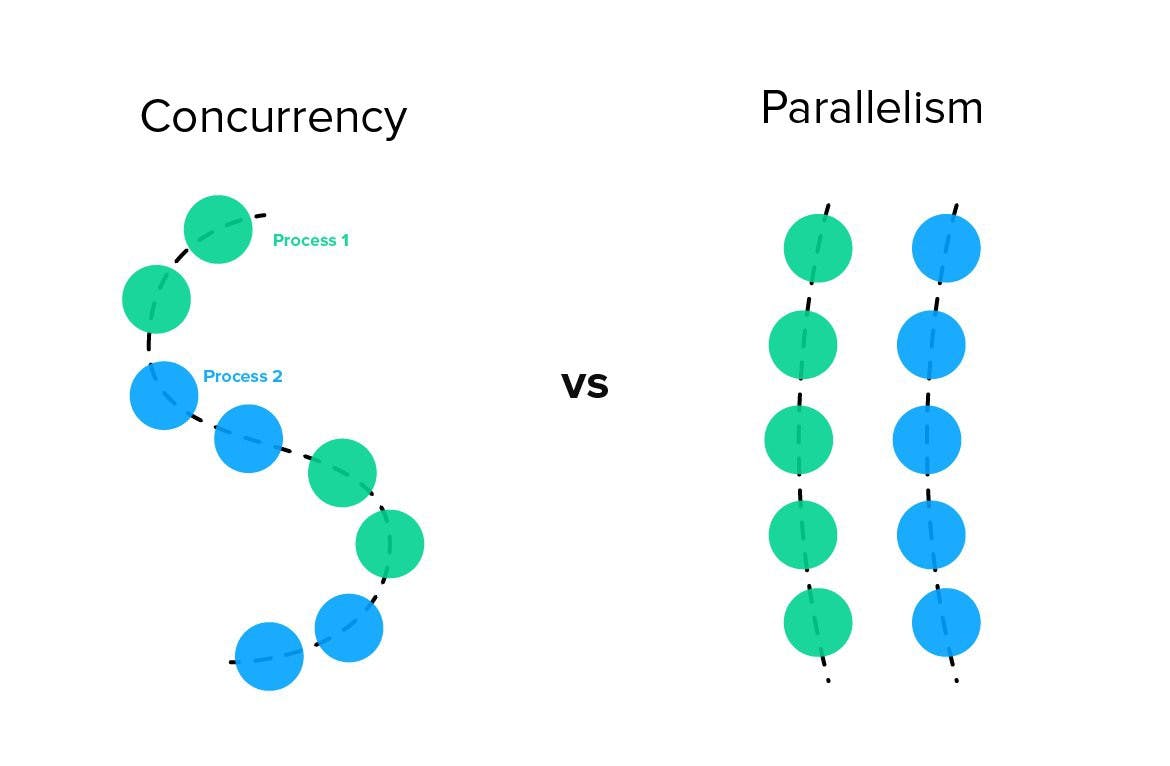
Parallelism
As a general term, it means that you want to do multiple actions at the same time, in programming terms it mainly refers to application tasks divided into smaller sub-tasks that are being processed simultaneously. Using multiple processors to achieve this helps in a faster execution in computational speed than running the processes sequentially.
An example of parallel processes would be in any normal scaling scenario where you have an operation and you want to increase work execution on multiple machines to run in parallel rather than waiting on a single machine to execute them on-by-one
Concurrency
Being ‘concurrent’ as a term usually refers to simultaneously which verbally is equal to ‘parallel’ but in our technical terminologies they have their differences, running concurrent processes relates to running more than one task independently in overlapping periods; meaning this might eventually reach each other but that’s not the target here, running concurrent processes means that they can run in no particular order. So a concurrent program has more flexibility than parallel execution.
An example of a concurrent process would be having multiple jobs being executed at some time and they don't wait for a certain order, they execute and exit when they are done
Why build a concurrent program?
Concurrency’s main power comes from the ability to execute threads by using a single processing unit! meaning it does not require multiple processors or CPUs to achieve threading in a software program, unlike parallelism.
Adding to this, concurrency increases the amount of work finished at a time since in some cases the order of the multiple tasks running concurrently doesn’t matter as long as they all eventually succeed and exit.
But don’t consider concurrency as a low-hanging fruit easily grasped. Like any applicable theory in programming, it does have some drawbacks that we will discuss along the way. However, applying concurrency using Go gives a solid ground for establishing concurrent programs if you know the magic words
Concurrency in Go
Go establishes concurrent programs by using a process called ‘Communicating sequential processes’ also known as CSP. This process originated back in 1978, it consists of three main points for handling communication with multiple processes (i.e same as concurrency in modern programs)
Each process is built for sequential execution; which is helpful since most of our programs are designed to run in sequential order, even writing a program has better readability when written in sequential, so that’s a big plus for CSP since it elaborates that we won’t change our methods of thinking when implementing concurrent programs using Go.
Data is communicated between processes through a medium; this rule binds us that we need to have a layer responsible for the transportation of data between our processes without interfering with the main process while the processes would work in their local state (i.e no shared state).
For scaling, we would apply the first 2 rules and it should be simple, assume we need to have a new process introduced within our program, we would simply add its behavior in the correct order within the code and have it communicate with the data transportation medium and tada it’s done! So scaling should be simple and straightforward by following the standards of CSP.
We’ll be taking a look at the toolset provided by Golang including Go routines, Channels, and WaitGroups. In which we will define some methods and accessories that Go provides for use to establish concurrent-friendly programs. Let’s start with the first one; Go routines.
Go routines
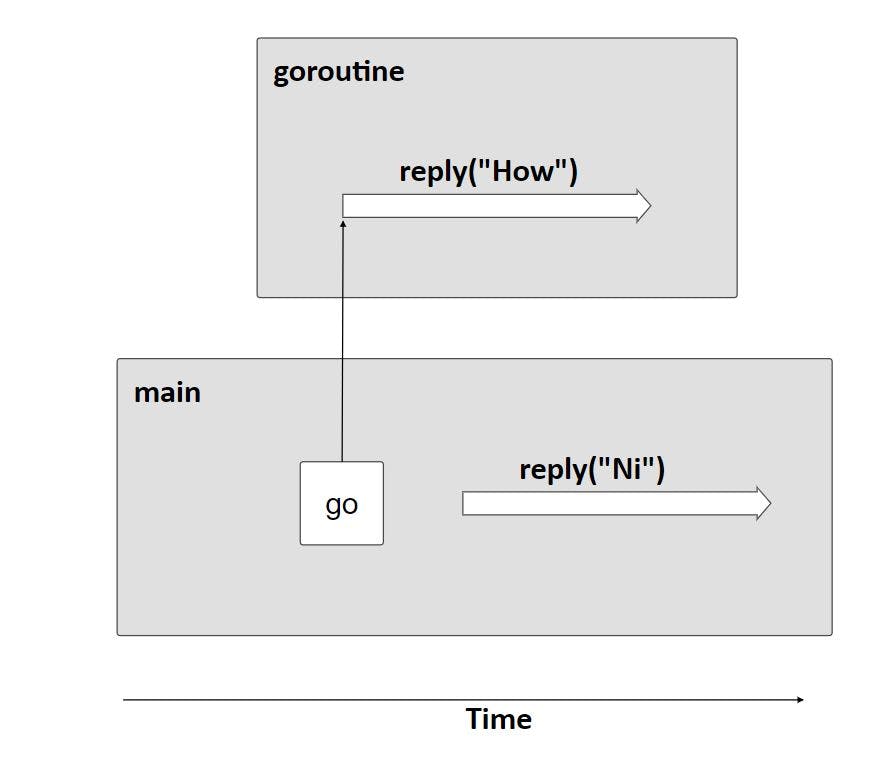
Go routine is a function capable of running concurrently with other functions in your program, simply by adding the keyword go at the start of calling the method we define in Golang that this method will be running on its own thread.
package main
import (
"fmt"
"time"
)
func reply(s string) {
fmt.Println(s)
}
func main() {
// A normal function call that does something and waits for completing it
reply("Ni")
// A goroutine that does something and doesn't wait for completing it
go reply("How")
time.Sleep(time.Second * 2)
fmt.Println("done")
}
The expected output would be
> Ni
How
done
Golang now understands this method to be run concurrently, Now your code has two go routines not one, why 🤔? since originally the first go routine assigned is the execution of the main function (compiled programs such as Golang require a main function as an entry-point for executing its logic), the second go routine is the one we just defined.
But why did we add the time.Sleep(time.Second * 2) ? let's check the output if we decided to remove the delay:
> Ni
done
What actually happens is that the go routine output was not returned as if the method wasn't executed. However, the method was executed but it didn't finish since we already established that a given go routine does not wait on the main thread.
This explains why we added the 2 seconds to delay the main process till we receive the output from the go function when calling reply since the main method execution won’t wait for its execution.
Moving forward, we now can have multiple functional blocks running concurrently which is great for a start. But like any program growing, the more services/threads we will include in our application, the more certainty we need.
This requires a sound structure with solid communication between its services. This is where we will be talking about channel communications
Channels
Overview
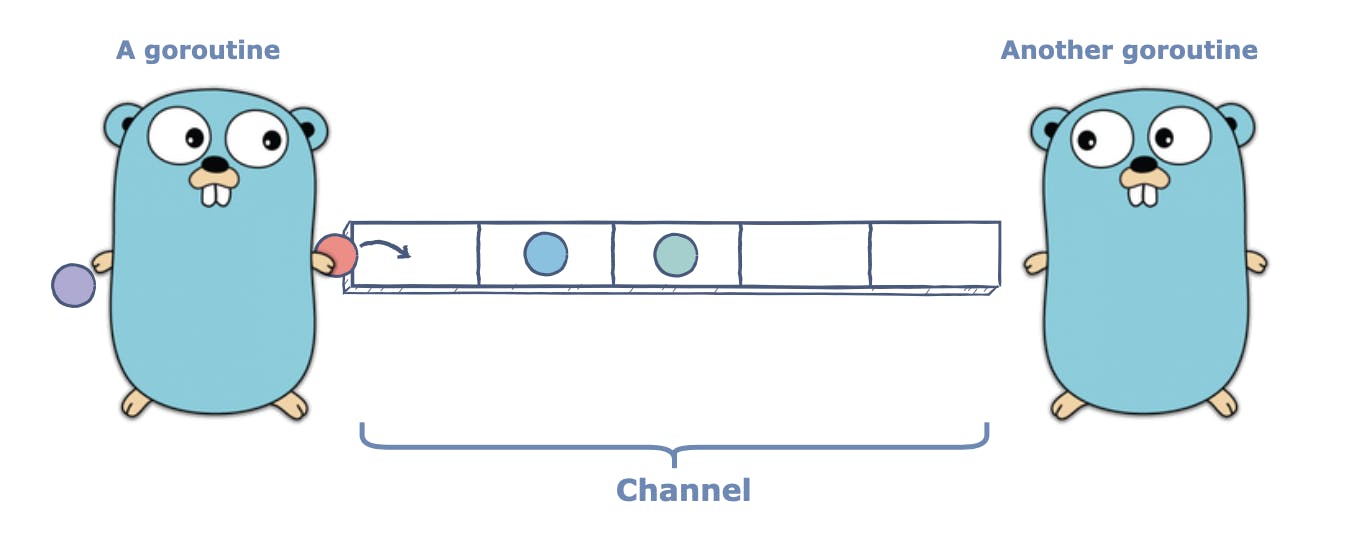
Channels are our main form of communication between go routines, channels consist of 3 main parts:
The sender, which is the one containing the information and requests to pass this data somewhere.
The buffer, which orchestrates when to start the handshake of send/receive actions.
The receiver, which the one pulls the data from the channel pushed from the sender.
Morning coffee
A quick example is getting some morning coffee on your way to work ☕️, you request some iced coffee from the drive-through machine (i.e the sending step) and wait in line while the coffee machine makes the orders (we can consider this step the buffering step) till your coffee is ready for you to pick up your order (i.e the receiving step).
The more cars in line, the more organized the drive-through needs to be to handle the high loads of orders of people requesting their morning coffee. People not receiving their morning coffee would panic, the same goes for Golang processes, they literally panic! if they are not able to receive the data requested (we will talk more deeply on this point later)
One note here is that the buffer is optional in most cases, meaning that it’s not necessary to use a buffer when communicating between processes, a coffee machine can do one cup of coffee at a time, and the buffer here acts as an optimization step.
As long as the communication is established and in a ready state, processes are able to send/receive data through the channel. The buffer only acts as an intermediate holder of data to stall the handshake between both processes if required.
Working with channels
Let's simulate the coffee order using go channels, we will start by initializing a channel for sending/receiving an order:
// Unbuffered channel of coffee orders
driveThrough := make(chan string)
// Buffered channel of 5 coffee orders
buffereddriveThrough := make(chan string, 5)
Now the drive-through is ready to receive the order, we need to define the sender/receiver blocks
Depending on whether we need to push/pull from the channel we need to define what is called a data direction in the channel, for example, say we want to push a message (i.e say our coffee order), we will be using the channel <- sender action for go to understand that we want to send a message in the channel
// Send an order through the channel.
driveThrough <- "Can i get one large iced latte please ?"
The same goes with pulling a message (i.e receiving your order) we will define the data direction using the reciever := <-channel action. Now go would understand that we request to pull some data from the channel
// Got your morning coffee, everything is better now.
order := <-driveThrough
Channel blocking
So far we were able to define channels and understand through channel direction how to push/push data from a certain channel, but channels are not always ready for the transaction. In some cases, a channel can be blocked! using what we learned so far we can determine some cases where the channel can be considered to be in a blocking state:
- Sender with no receiver → The sender is waiting for some one to pull the data but there’s no process in line so the sender is blocked
// Coffee machine is OUT OF ORDER, Panic!
driveThrough <- "Are you guys open? i need my coffee."
- Sender with another process waiting in line → the sender wants to push the data on the channel but the buffer is full at the current time, so the sender here is blocked
// A coffee enthusiast is very picky in-front
buffereddriveThrough := make(chan string, 1)
buffereddriveThrough <- "Coffee-Enthusiast: Can I get a venti Spanish latte with coconut milk ..."
buffereddriveThrough <- "You: Excuse me, when can I order my coffee 🙄??"
- Receiver with no orders in line → the receiver wants to pull some data but the process in the chain beforehand has no messages so the receiver is blocked
// You're waiting for your order, but you forgot to order :(
buffereddriveThrough := make(chan string, 1)
// Waiting ..
yourOrder := <-buffereddriveThrough
Closing channels
When every order is done, channels like drive-throughs can announce themselves closed. Sending/receiving from a closed channel would not do any action in that case. Simple use thew keyword close, we can announce a channel to be closed like the following:
driveThrough := make(chan int, 1)
close(driveThrough)
fmt.Println(<-driveThrough)
But what are we expecting to receive from this line when it's executed 🤔? we already closed the channel. That is where we will discuss the 2-values parameters defined for channels.
2-values channel parameter
Golang is smart in handling empty states and failures 💡, when we closed the channel we should expect that the program will fail when requesting to print the data received from the channel. However, we will receive the following:
> 0, false
A receive always returns two values:
The
0here which is the first value is a default value of no job (since the example was integer if the channel expects strings the default value would be an empty string)The
falsehere is usually assigned to a value namedmore, it’s mostly used as an indication if there are still jobs remaining in the channel not pulled yet by processes
Collecting the pieces
Now, Let’s make the coffee drive-through more advanced:
package main
import "fmt"
func main() {
orders := make(chan int, 5)
done := make(chan bool)
go func() {
// Endless loop
for {
j, more := <-orders
if more {
fmt.Println("received order: ", j)
} else {
fmt.Println("received all orders")
done <- true
return
}
}
}()
for j := 1; j <= 3; j++ {
orders <- j
fmt.Println("order: ", j)
}
close(orders)
fmt.Println("sent all jobs")
<-done
}
In the above example, we created two channels:
- orders for receiving the orders
- done as an indicator of when all orders have been received
we iterate in sending the orders and close the channel afterward, the go routine will iterate on the orders and print them as long as there are orders in the channel not pulled yet. Upon pulling all the jobs from the channel, we signal the done channel that we’re done and break out of the endless loop to return back to the main function to exit. The expected output would be as follows:
> order: 1
order: 2
order: 3
sent all jobs
received order: 1
received order: 2
received order: 3
received all orders
Follow up
So far we talked about what is concurrency and how Golang provides ways to develop concurrent processes using channels. Summarizing the above blog, we now have a better visual on:
- Concurrent programs versus parallel execution
- Golang's toolset in applying concurrent applications
- Go routines and their relation with the main thread
- Applying go channels and channel blocking scenarios
In the next chapter, we will be stressing more on channel blocking, waitGroups, and using a non-blocking approach through Golang.